How do you manage the data extraction?
How do you create the data extraction templates?
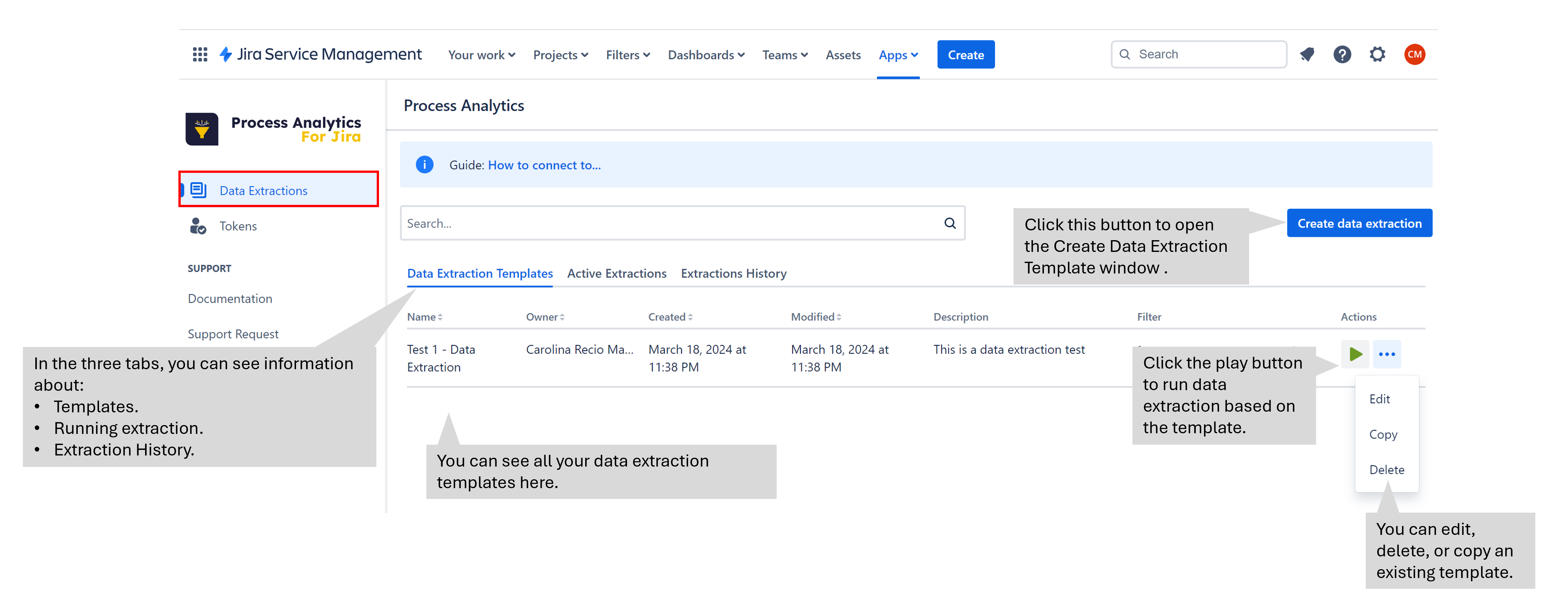
Steps to create data extraction templates, where you determine the set of data and the fields to extract in a CVS file, are below:
Click the button “Create data extraction”.
This action opens a new screen where you introduce the template information.
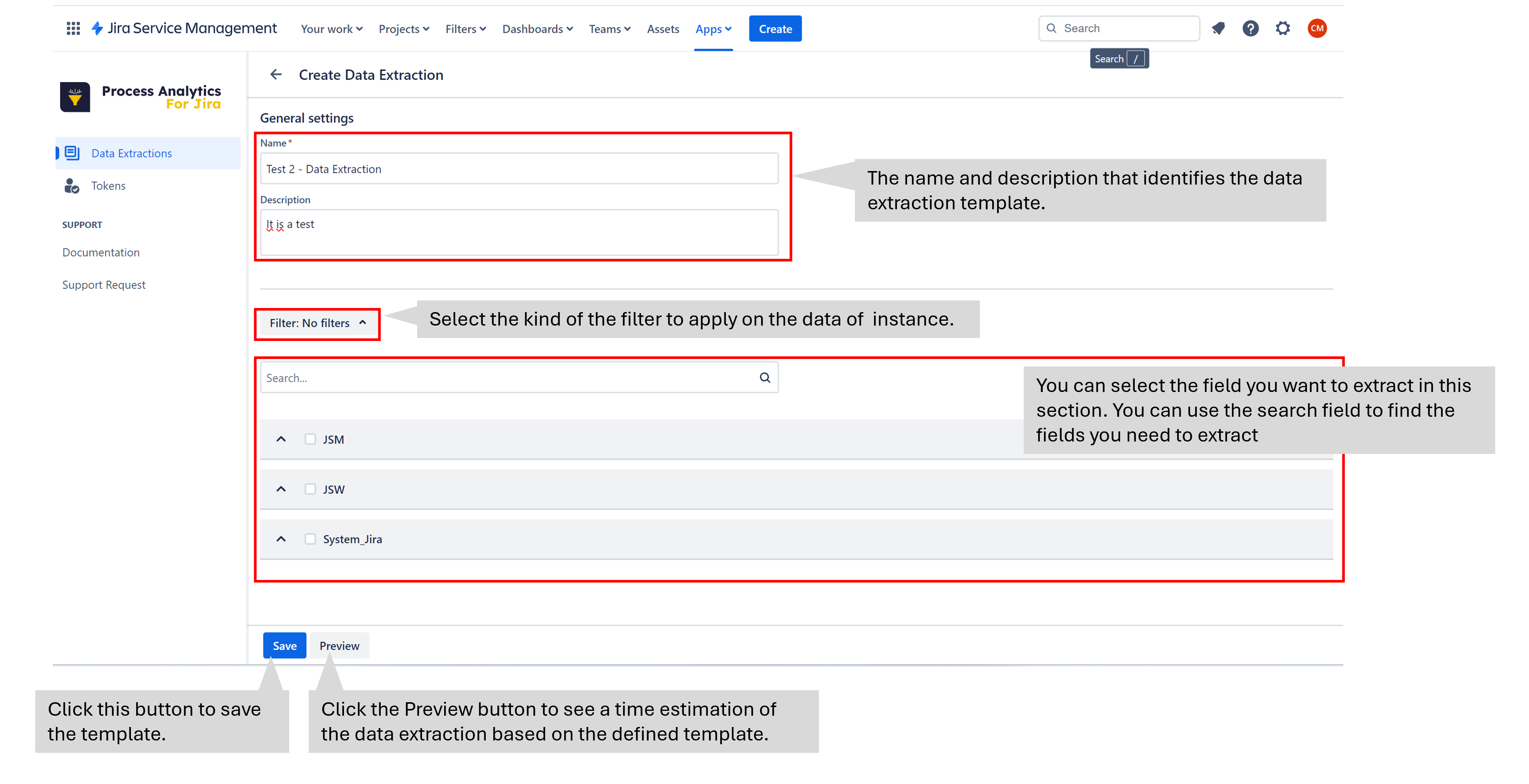
Kind of the filter to aply on the data of instance:
No filters: This option searches in every data of the instance.
JQL: You can introduce a JQL filter to extract some data from the instance.

Basic: You can select a filter saved in JIRA to extract some data from the instance. In the link “Create new custom filter” you can navigate to JIRA and create a filter.

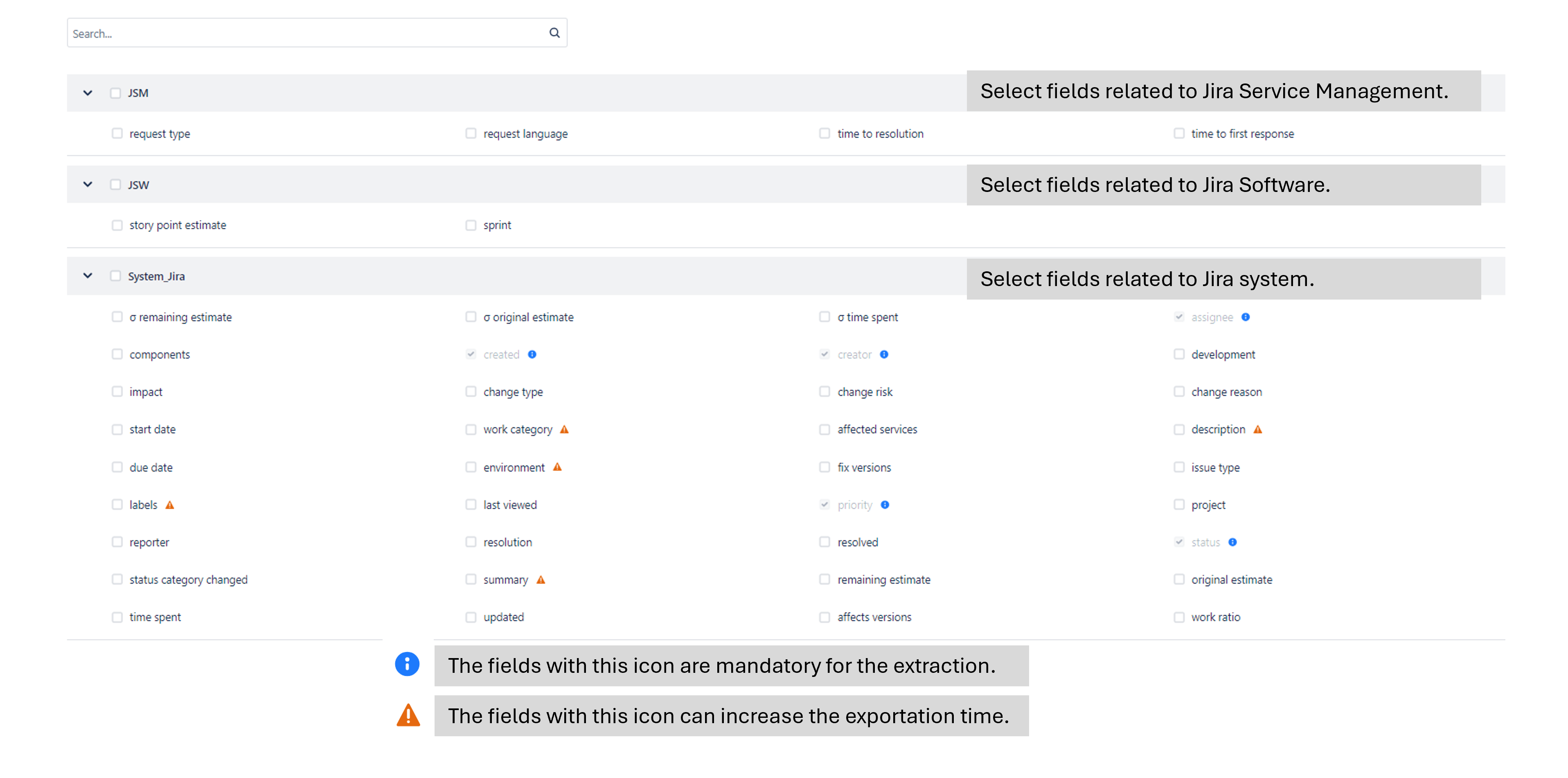
Selection of extraction fileds:
How do you run data extraction?
Click the play button to run data extraction based on the template. ![]()
When template is launched the extraction process appears in the “Active Extractions” tab.
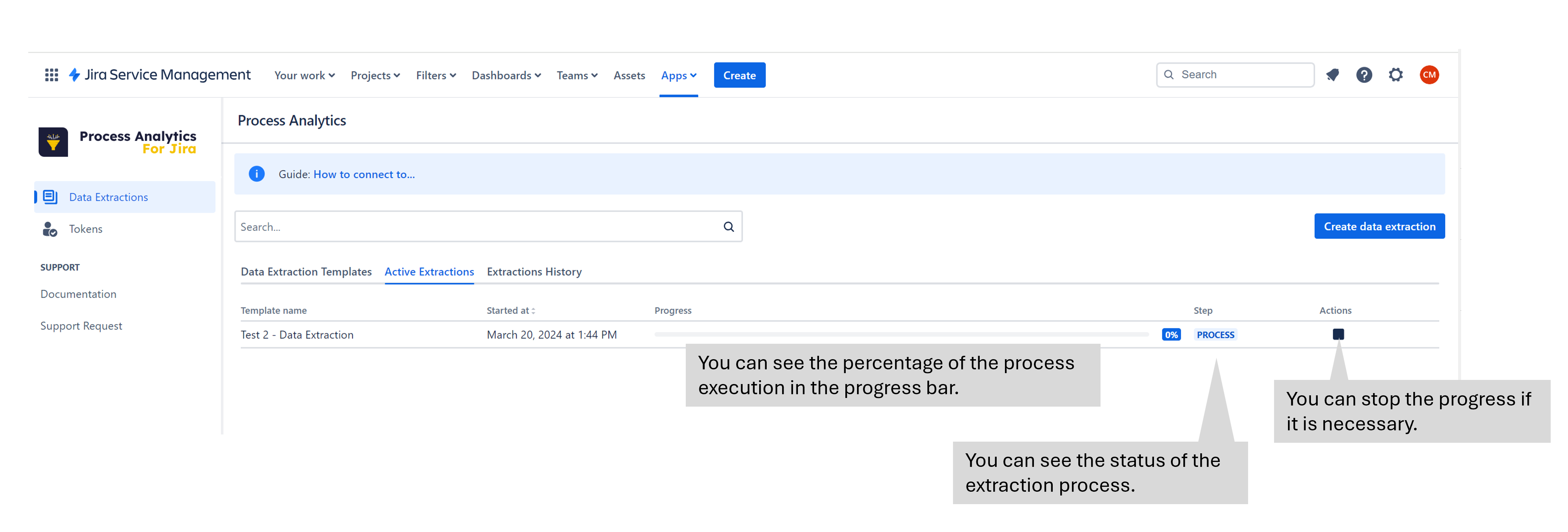
The progress bar indicates how the extraction process is advancing. The extraction status will be changing, too.
The extraction statuses are the following:
QUERY: The system is connecting the JIRA instance to extract the data. The JIRA instance is stressed.
PROCESS: The system is working, but the JIRA instance isn’t affected.
POST-PROCESS: The CVS file is processed to display the extracted metrics.
COMPLETED: The process has finished, and the CVS file has been prepared for download.
NOTE: Only one extraction can be run simultaneously per user and instance is possible.
What is the result of data extraction?
When the data extraction process finishes, you will get an email with a link to download the CSV file.
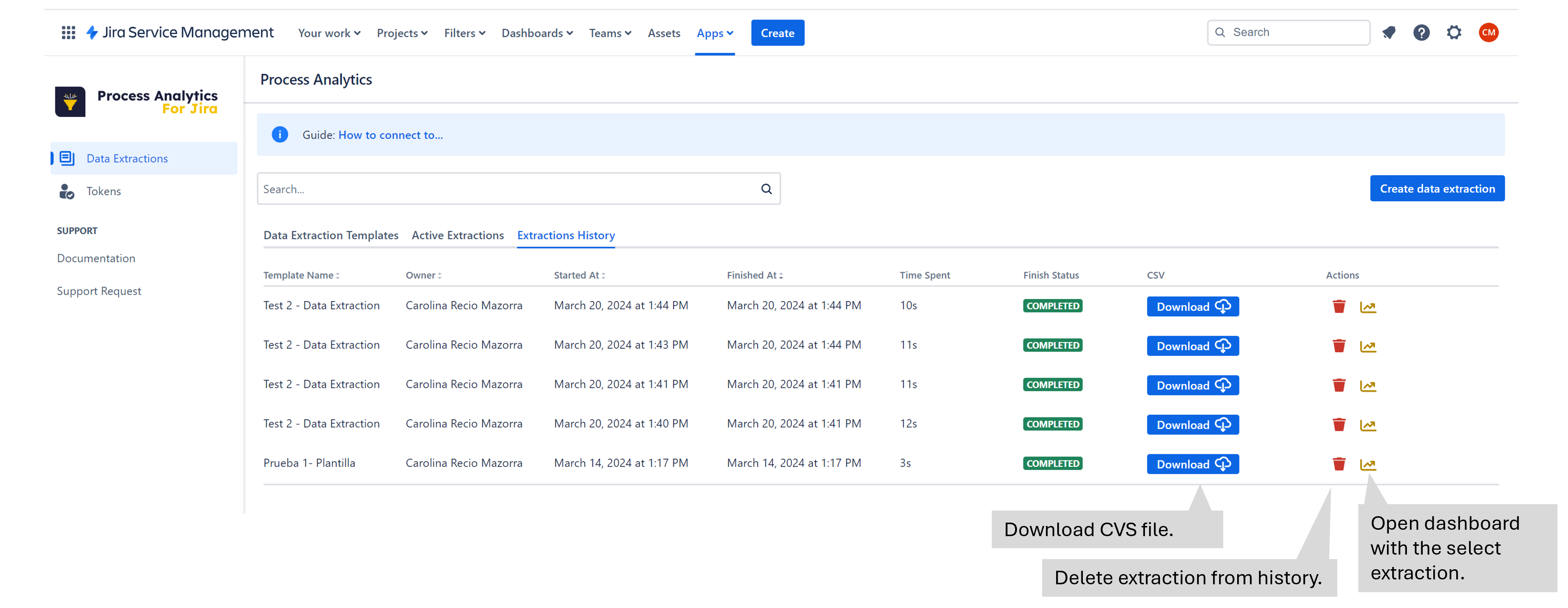
From the “Extractions History” tab, you can see a list of extractions run per the connected user. You can realize the following actions:
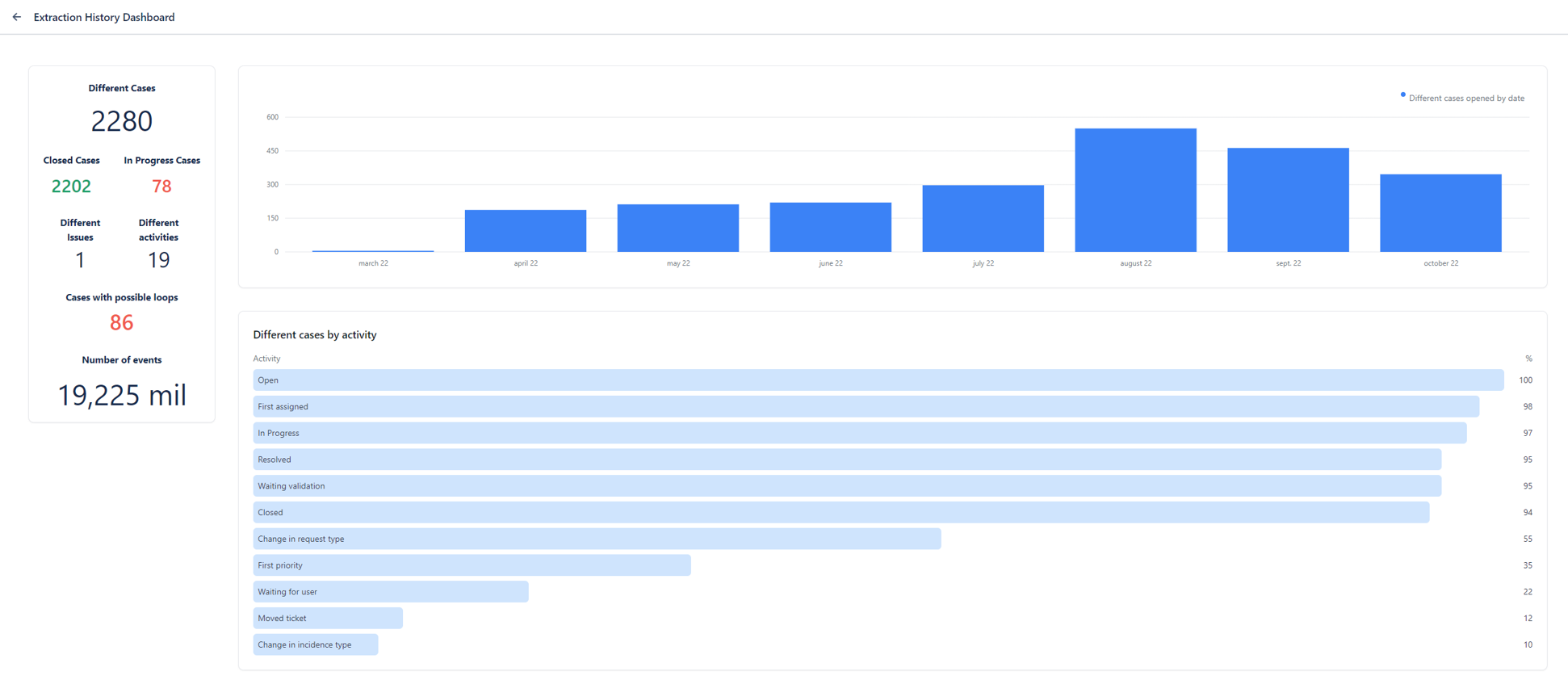
Below is an example of a Dashboard with extraction information.
You can obtain the CSV file with the extraction data from the link sent to your email or from the download button in the tab. The steps are below:
Go to the Downloads directory on your local computer.
A .zip file has been downloaded.
Extract the .zip file.
The CVS file is already available. Note: The CVS file has UTF-8 Encoding.
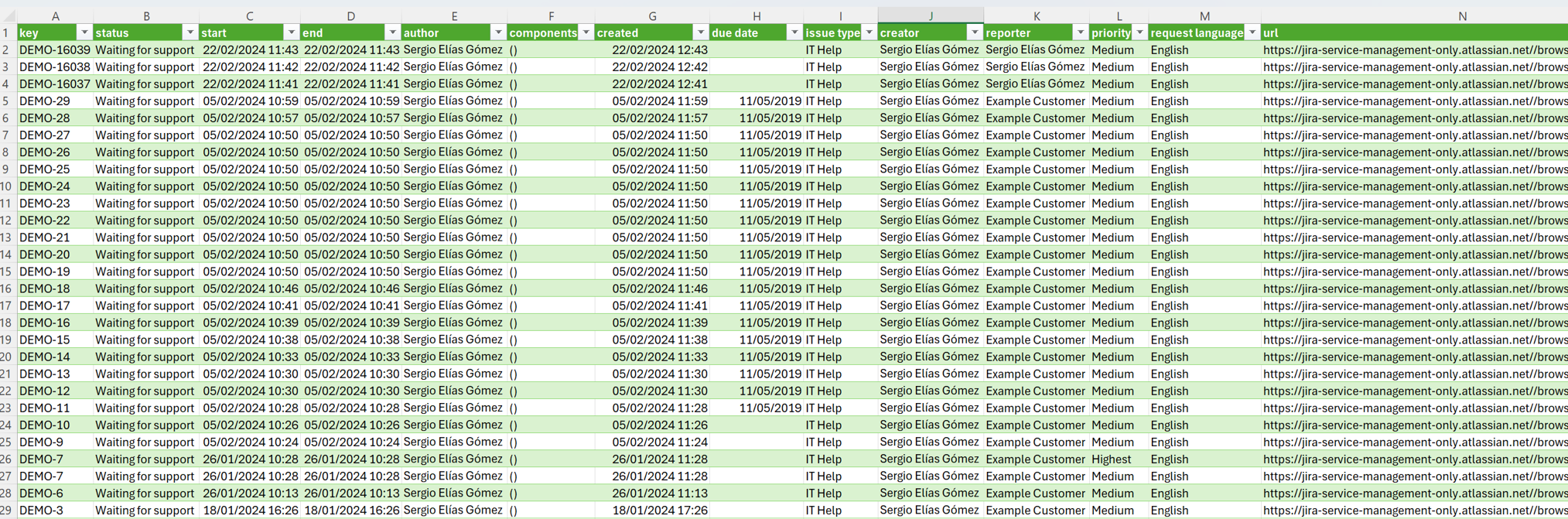
Below is an example of a CVS file with extraction information.
How does it use CVS in Process Mining tools?
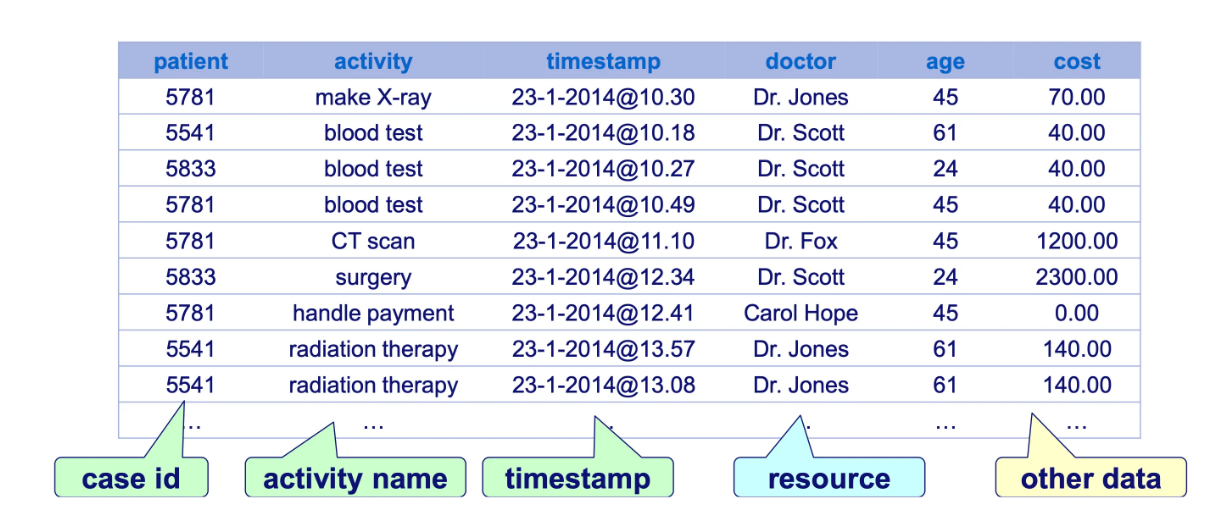
Process mining assumes the existence of an event log where each event refers to a case, an activity, and a point in time. An event log can be seen as a collection of cases, and a case can be seen as a trace/sequence of events.
Event data may come from a wide variety of sources:
A comma-separated values (CSV) file or spreadsheet.
A database system (e.g., patient data in a hospital).
A transaction log (e.g., a trading system).
A business suite/ERP system (SAP, Oracle, etc.).
A message log (e.g., from IBM middleware).
An open API providing data from websites or social media.
Ideally, event logs are stored in the standard format for process mining XES. However, the native format is seldom and an event log. Often, Comma-Separated Values (CSV) files are used as an intermediate format. The rows in a CSV file correspond to events, and the columns to attributes of events. There should be columns for the case identifier, the activity name, and the timestamp of an event, but there may be many more attributes.
ProM and most other process mining tools (Celonis, Uipath, Minit, Apromore, Inverbis, etc.) can convert a CSV file into an event log by assigning columns to process mining concepts.